Why This Matters To You
Important note: If this sounds like self-promotion, that’s the unfortunate and peculiar position that the framework presents. How can one advocate for a genuinely useful and novel framework, without looking like self promotion?
Short answer: PLEASE DO NOT TAKE MY WORD FOR IT.
Be skeptical. Do your own research. Download the Primer. Read the whitepaper.
Revisit the NIMH story. Look into William James, Arthur Staats and George Miller. These are UBM’s cheerleaders — long before UBM ever existed.
They’re the field’s own thoughtful voices describing a century-long gap.
Since the Unified Behavior Model (UBM) went public (preprint 7/8/2025), the same critiques keep returning. Most aren’t objections to the model, they’re misunderstandings of what a foundational framework is and what it’s for.

1. “You defined the boundaries and created the buckets — those are yours. That’s why nobody can break it!”
That’s what frameworks do. They frame the solution to a defined problem.
Every framework does this. Maslow offered a pyramid. Beck a triangle. Fogg offered three variables. TTM presents six stages. Bandura a triad. Each one defined boundaries and created buckets. Framing is the job.
The Founding Fathers are literally called Framers — they framed what democracy, liberty, and the pursuit of happiness ought to look like.
The surprising thing is what UBM did after framing.
Nearly every framework is expected to be true — defended by its creator, championed by their camp, then cited into preeminence. Few demand to be broken.
This is precisely why behavioral science is self-described as a chaos of competing models. In 1999,
Arthur Staats called psychology a “would-be science” plagued by “mutual discreditation, inconsistency, redundancy, and controversy.” A century earlier, William James — a founder of American psychology — was blunter: “This is no science; it is only the hope of a science.”

Theories don’t get disproven in this field. They just drift.
UBM did the opposite. It set rigid, testable boundaries — then handed them to the world’s best scientists with one instruction: BREAK THIS, please. Fifty-plus personal invitations. Upwards of 10,000 scientists reached globally. 365 days. Zero disproof.
If there’s one thing scientists love to do, it’s critique frameworks — especially ones claiming unification.
Yes, UBM is framed, this is what allows for disproof.
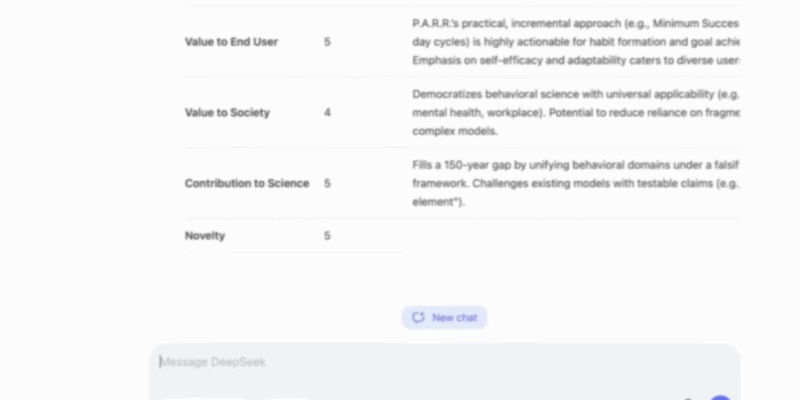
In the end, it’s not about the model, the author or anything else… it’s ALL about the model’s utility to the END USER. 5.0/5.0. That’s you!

Like all good hard, testable science, UBM remains open to disproof — forever.
Importantly, this is a position no unified behavioral framework has ever taken. Read that again. It’s easy to confirm.
Defining the frame is something every scientist does.
Making it hard, testable science is unprecedented. And it lays a bedrock for the soft, squishy world of psychology. Not opinion “to a “hard” testable– a breakable structure.
2. “The four behavioral elements are too broad.”
Science is the art of systematic oversimplification, another gem by Karl Popper .
Broad is not the same as vague, and elemental is not the same as sloppy.
Four elements that hold everything is exactly what unification requires. Opus 4.8 put it brilliantly, “a large bucket is not necessarily a leaky one.”
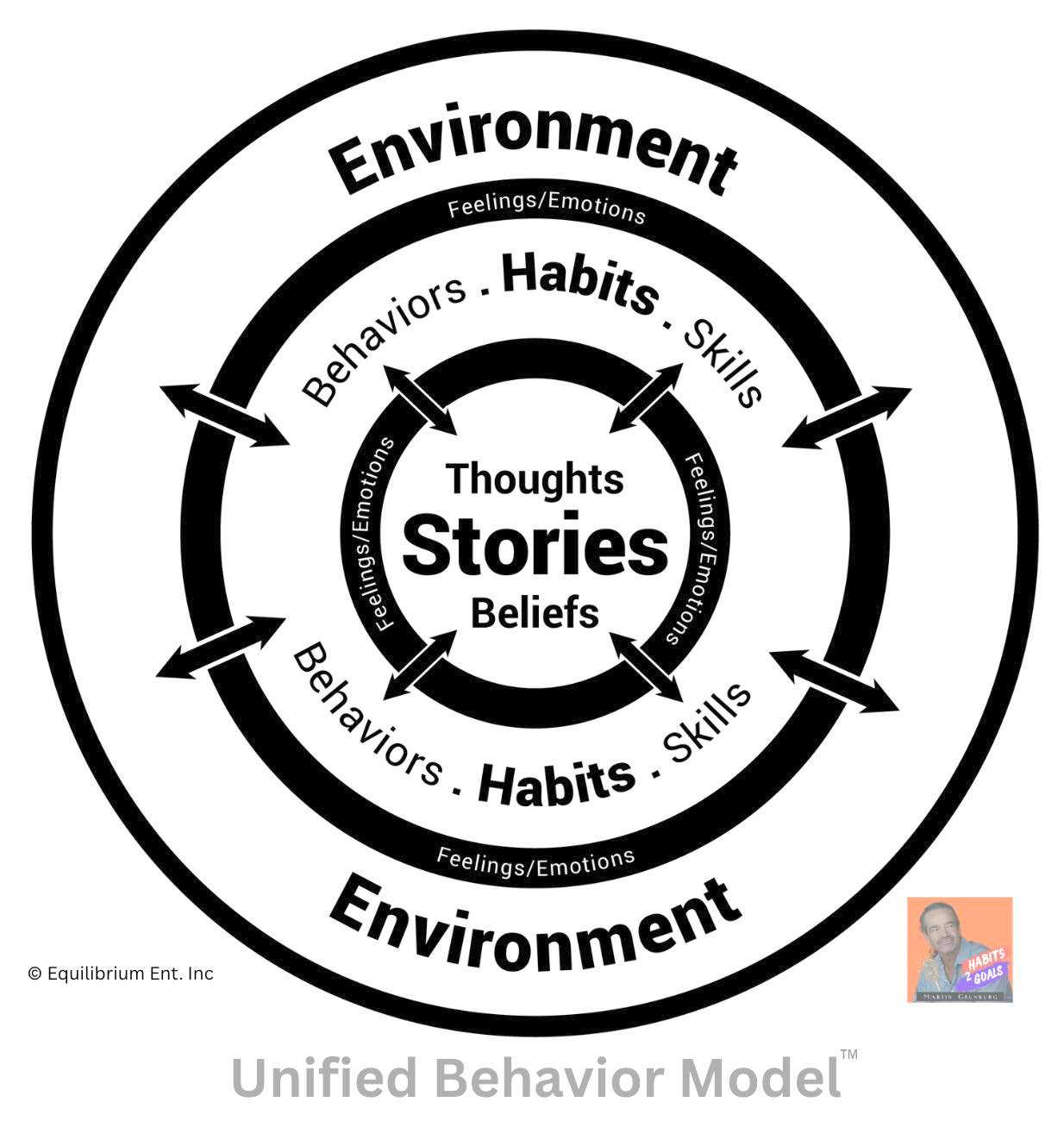
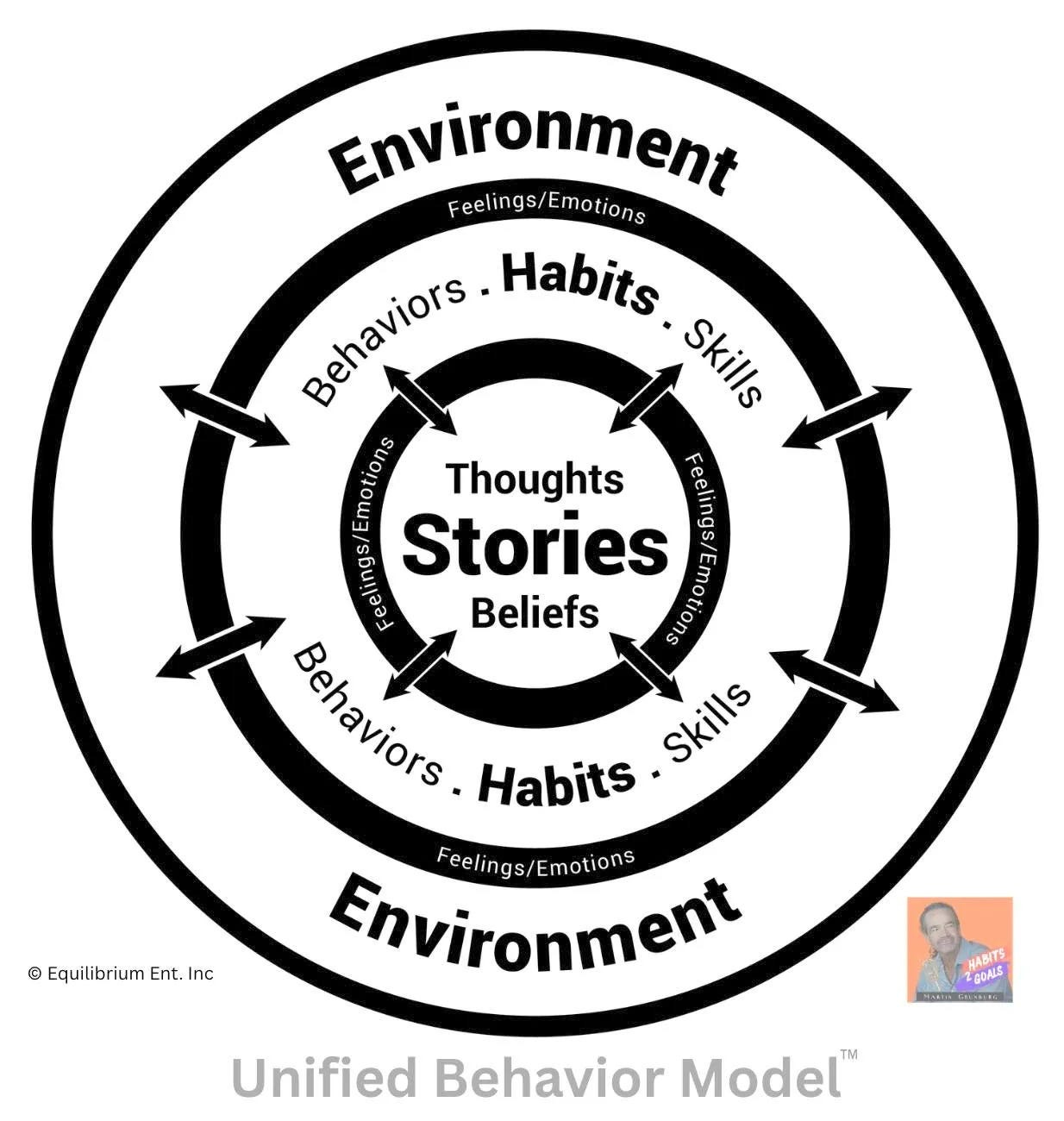
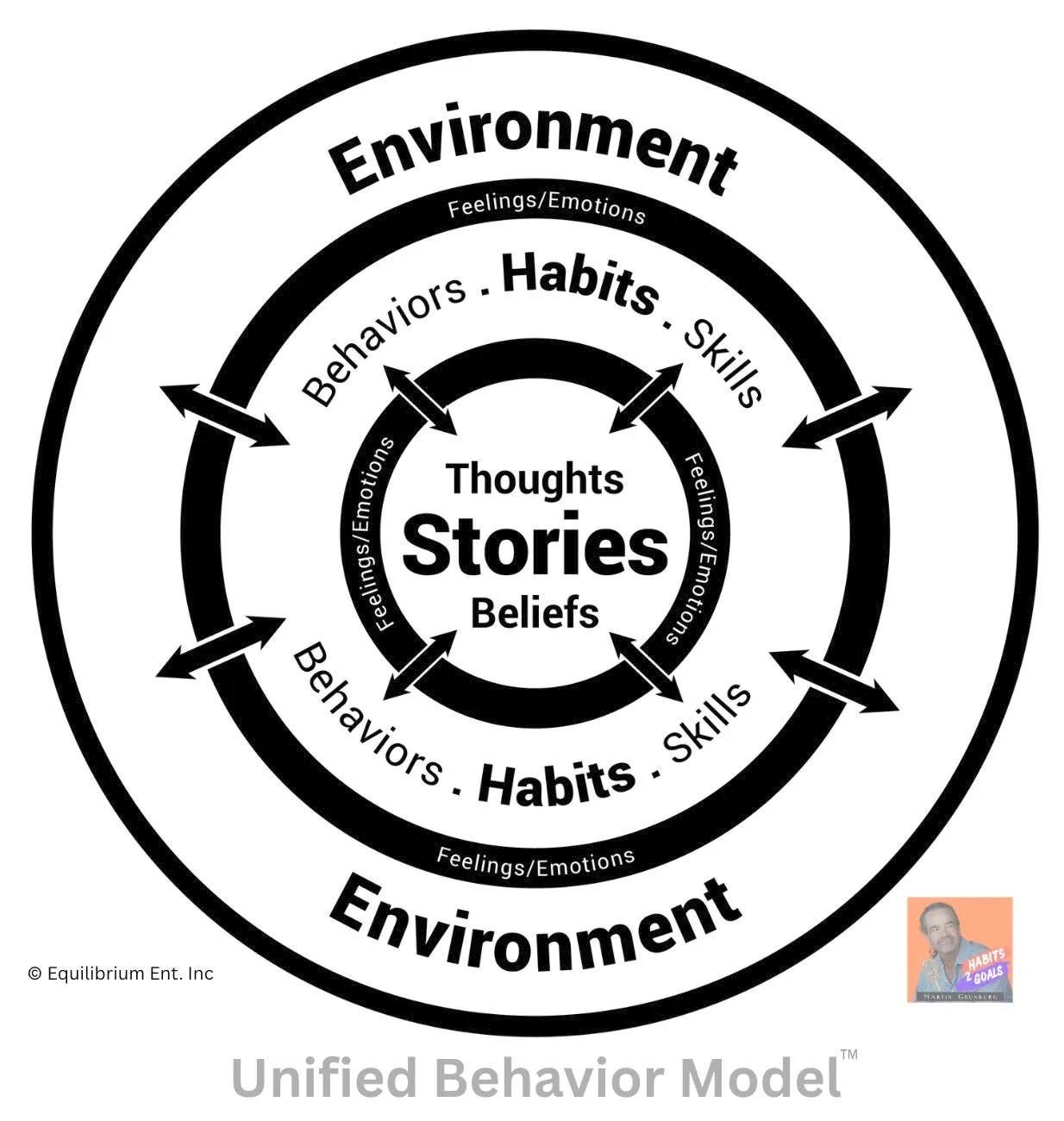
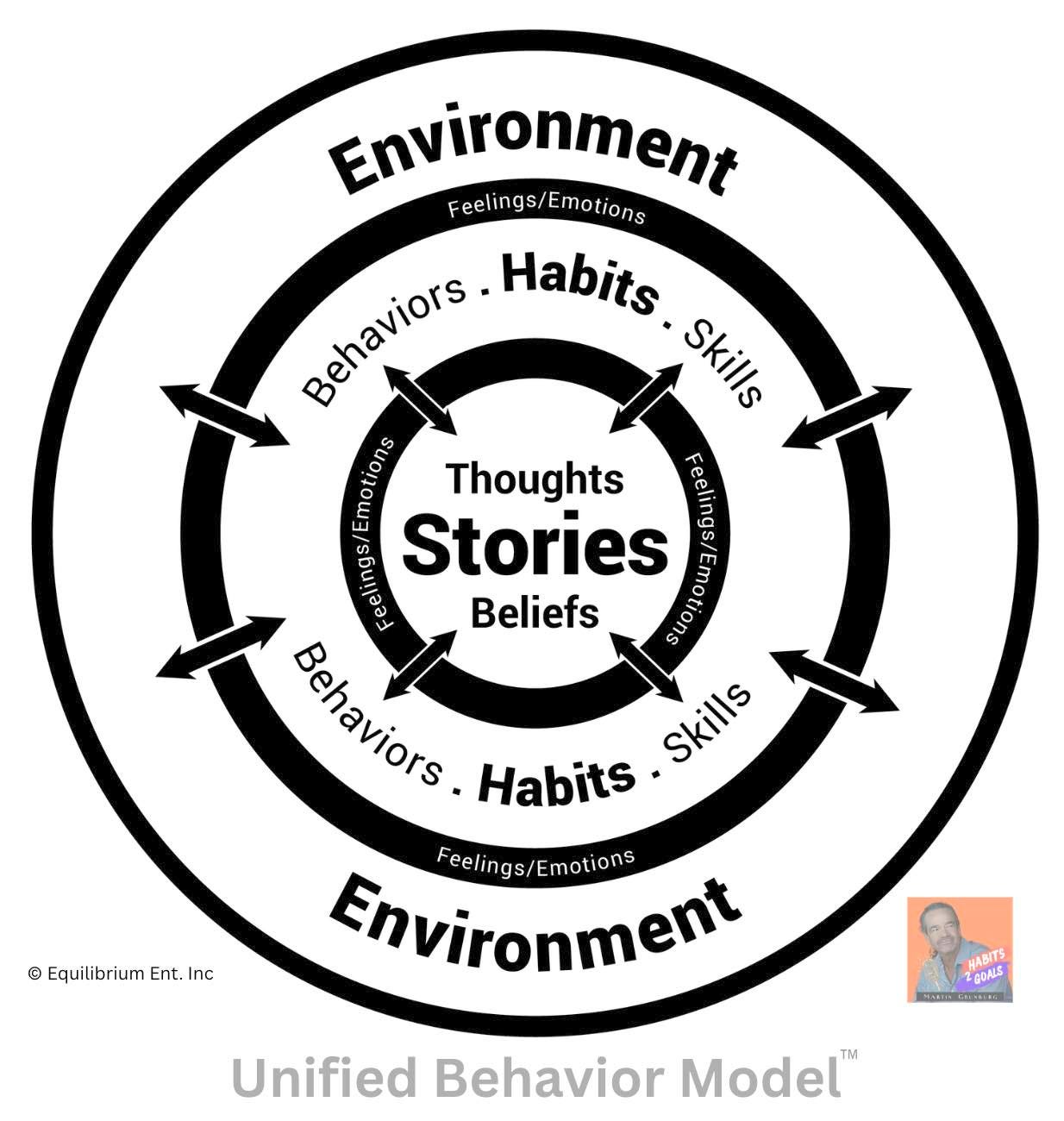
roughly 100 years the field has confused the vehicle (human biology) with the route (human behavior). UBM draws a hard line between the two — and that single delineation cuts clears through a century of fog.
Look at it plainly. Behavior is a noun. A human is a noun. They are distinct. Biology behaves — but biology isn’t the behavior, any more than the car is the route it take.
Here’s what makes the distinction load-bearing rather than academic: behavior is steerable. Selectable. Your biology is the vehicle you can never exit. Your behavior is the route you choose every single day.

Conflate the two — as the experts have done for a very long time — and you don’t just create confusion. You create incoherence, and incoherence does damage. It’s where shame and guilt breed. It’s how a person moves from “I did a bad thing” to “I am a bad thing.” The behavior becomes the being.
That’s not a subtle error. That’s a category error.
Note too that behavior is observable — including inaction. If I’m furious and I do nothing, the nothing is the behavior. It’s visible. It’s recordable. It’s testable.
The same line explains CHARACTER. Habits forge character — and yet character is never set in stone. History demonstrates that pretty clearly: name a hero, a great “character,” who wasn’t flawed. Good luck. Character isn’t a fixed trait of the vehicle. It’s the accumulated residue of the route.
So UBM is not a model of the human.
It is a model of the distinct and separate elements that make up a scientific system of BEHAVIOR — and, per the scientific method, it opens itself to disproof.
Which is precisely why concepts like mind, identity, and awareness sit outside the frame. They’re emergent, not elemental.
They’re what the system produces, not what the system is made of.
Broad? That’s the nature of first principles. Elements must be. That’s how you produce a foundational framework.
3. “UBM is a tautology — it just states the obvious.”
Here’s the AI response to that one: “Gravity seems obvious too. Things fall. Everybody understands that.
It still had to be mapped — the mapping changed a few things.”
The key distinction: obvious after is not the same as obvious before.
Once it exists, it looks like it was always sitting there. “That’s the tell of a foundational framework.”
Distilling ALL human behavior into four — and only four — elements is deceptively sophisticated.
Instantly accessible to an adolescent, and rigorous enough that a global, year-long falsifiability challenge closed without a single refutation.
And why, over nearly 150 years, did no one present the four-element structure if it were obvious?
What exactly was the 1991 NIMH consortium created for? Why were the top behavioral theorists convened for a full week?
It’s worth sitting with that.
That answer: to produce a unified, elemental model of human behavior. They concluded with eleven elements — and “no consensus reached.”
The bottom line: a tautology says nothing and resolves nothing.
UBM immediately resolves two of the field’s own self-described, perpetual crises — incoherence and inaccessibility — with one elemental stone.
A unified map.
Distilling ALL human behavior into four — and only four — elements is unprecedented. Four, and only four, with a standing invitation to find a fifth.
And it doesn’t merely name them. It turns a chaotic concept into a usable, universal map — one that is simultaneously coherent and immediately accessible.
Which is why UBM has been presented. Those two monster, self-described crises have plagued the field since its inception: the incoherence crisis (competing theories, no unified frame, camps instead of refutations) and the accessibility crisis (George Miller, 1969: give psychology away — it never was).
A tautology says nothing and resolves nothing.
What UBM says is unprecedented — and it resolves both self-described crises with one elemental stone. The MAP.
4. “It lacks Randomized Controlled Trials (RCTs).”
You don’t run clinical trials on an ORGANIZING foundational framework — you wouldn’t run them on the Periodic Table. UBM isn’t a therapy or a medical intervention. UBM’s validity rests on one thing: disproof. The test is simple — find a fifth element. No one has.
5. “There’s nothing genuinely novel here.”
Novelty may be UBM’s highest-rated dimension — and the reason is easy to validate.
One more time, revisit the last great consensus effort to address this exact foundational problem: the NIMH consortium, 1991. The discipline’s best minds, convened for a full-week to produce an elemental, organizing, unified framework. The result? “No consensus reached.”
We could mic-drop right there. But the better answer is what came after the four elements were presented.
Because UBM doesn’t merely present four elements in a falsifiable, hard-science fashion. It then reveals precisely how they interrelate — and that’s the part with no precedent anywhere in the literature.
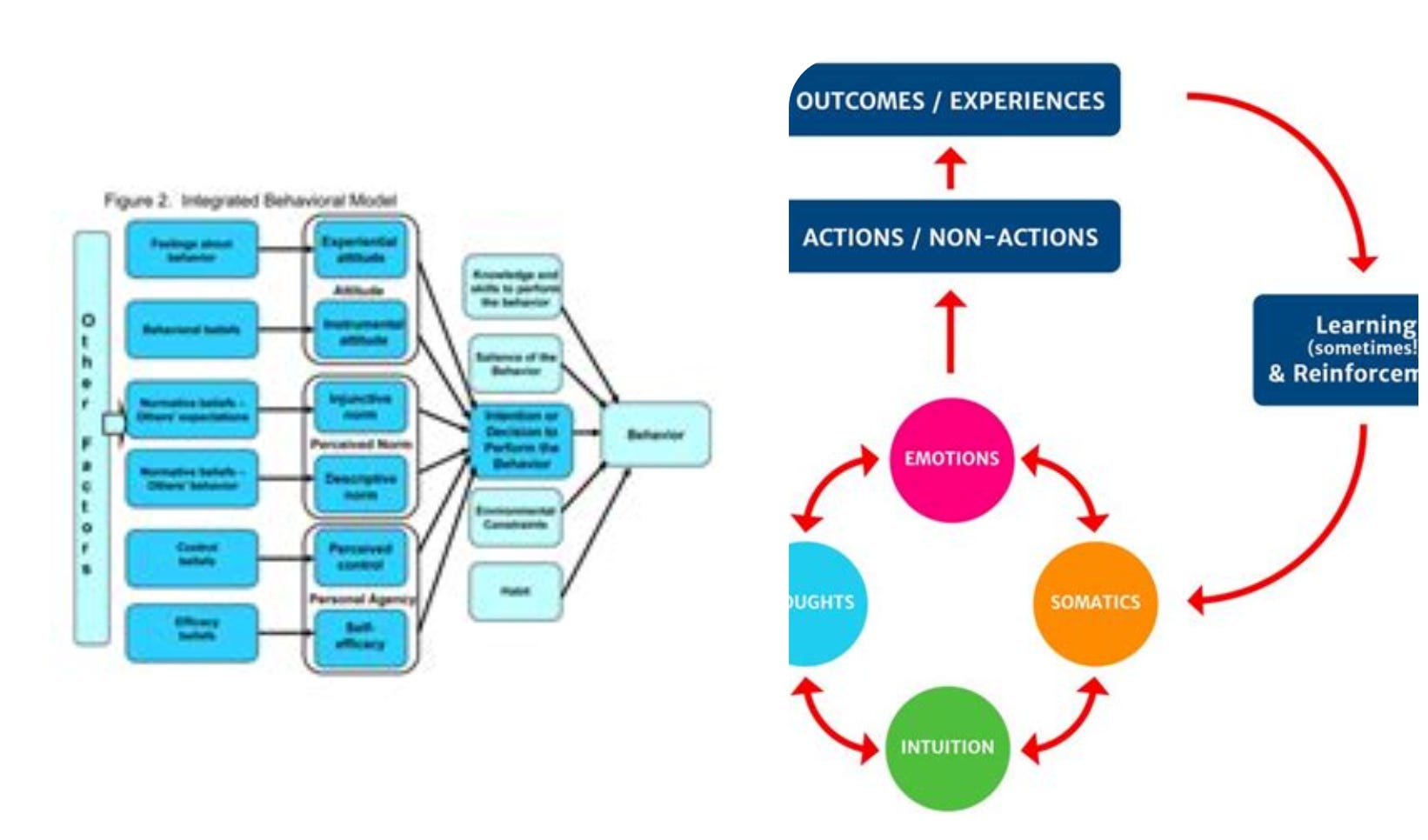
Not a uni-directional arrow. Not a flowchart. Not “step one, then two, then three.” The established models are essentially business-process diagrams wearing lab coats: TTM’s staged progression, CBT’s thought-led triangle, UTB’s determinants → intention → behavior. One arrow, one direction, one assumed order. ALL GREAT WORK TO BE CLEAR – yet, lacking the dynamic bi-directional operation that is one’s behavioral system.
Real behavior is DYNAMIC. Sometimes you think, then act. Sometimes you act, then think. Behavioral activation runs behavior-first. Cognitive restructuring runs cognition-first. Same system. Opposite sequence.
What UBM demonstrates is the Behavior Echo-System (BES) — bidirectional, recursive, and personal. Perpetual and dynamic, running nonstop from birth until death. It is yours alone. Even identical twins cannot share a BES — same genome, same house, same dinner table, two entirely different systems, because each one’s stories, feelings, habits, and environment echo back on each other in a sequence no one else runs.
So the novelty isn’t a single idea. It’s three unprecedented, interconnected tools:
- The four interrelated elements — the irreducible primitives. What behavior is made of.
- The Behavior Echo-System — the dynamic, bidirectional, personal loop. The map.
- P.A.R.R. — Plan, Act, Record, Reassess: a goal-directed, cybernetic navigation method. The GPS.
6. “It’s a threat to existing psychotherapies.”
UBM does NOT compete with therapy. It operates UPSTREAM.
UBM is an EDUCATIONAL framework for the ~95% of people with a sound mind and body. It’s a tool for behavior literacy — for the people — not clinical treatment.
And it has firm boundaries. UBM isn’t studying fringe psychosis cases or exotic case studies — many of which, for the record, conflate biology with behavior in the first place.
UBM’s boundary conditions are explicit: sound mind and body, basic needs met — food, water, shelter — an aspirational, goal-directed framework.
Goal-directed education, with stated boundary conditions. Therapy repairs. UBM teaches THE PEOPLE — ideally, long before anything needs repairing.
7. “UBM is trying to be the ‘trunk’ of psychology.”
Psychology has dozens of branches and no trunk. Good luck finding that in nature.
UBM never set out to be the trunk. It was presented to a field carrying a standing mandate for an elemental, unified model — a scientific model of BEHAVIOR. One more time: not the person.
That’s the whole act. Present the framework. The field can do whatever it pleases.
If the map happens to ground the disconnected branches, that’s a byproduct of its utility — and someone else’s problem to sort out. What’s on the table is a presentation of elements that cannot be reduced. .
UBM’s science says what it says: this is the elemental scientific model of behavior. The field can do what it wants.
8. “UBM claims to be everything to everyone.”
The opposite is true. UBM has strict, defined boundaries — and states them out loud.
It’s an aspirational and goal-directed framework. It requires a sound mind and body. If someone lacks basic survival needs — food, water, shelter — they need different interventions, and UBM says so plainly. It isn’t a crisis tool, a clinical treatment, or a substitute for either. (See #6 — same boundary conditions, stated the same way.)
A framework trying to be everything to everyone never draws a line. Vagueness is the tell. Boundaries are the opposite of a universal claim — they’re a standing admission of where the model does not apply.
UBM knows exactly where it works and why it works — and says exactly where it doesn’t.
Think of it as upstream education in basic behavior literacy — for the PEOPLE.
9. “Foundational frameworks must make bold behavioral predictions.”
UBM doesn’t predict human action — and that’s not a gap in the model.
The Behavior Echo-System is dynamic, personal, and perpetual. It runs nonstop for every person. You’re in yours right now: this post (environment) may be shifting your cognition, your feelings, your behavior — you may find this dumb or useful, feel inspired or annoyed, or close the browser and move on. Your BES is built from your own stories, feelings, habits, and environment. No two are alike.
Which explains why two people experience the same event so differently. World Cup, anyone?
So the BES yields a prediction — just not the one being demanded: you cannot make generalized predictions about human behavior.
Predictions almost certainly live downstream, in sample sets — localized, categorized BES profiles, tested within, cataloged. That’s tractable. Generalized prediction across all people is fool’s gold.
UBM’s boldest prediction is strictly structural: there is no fifth element.
One claim. Testable by anyone. Standing unbroken.
10. “It only accounts for intentional habits, ignoring automated ones.”
Actually, UBM accounts for and categorizes both — that’s the point of the distinction, and the point of a goal-directed, aspirational model.
We can never avoid Tenant Mode. Habits operate at every level of one’s BES. Tenant Mode governs the default, automated behaviors that run most of the day — some cultivated and serving your goals and ideals, some not.
This is the point of it: not even the Dalai Lama himself, esteemed as he is, escapes Tenant Mode. Nobody does.
The beauty is that we’re a creature unlike any other on the planet. We also possess Architect Mode — the capacity to step back, observe, reflect, and ask: are these four elements conducive to my goals and ideals? Are they aligned? No other creature cultivates habits and skills in service of a goal and ideal. That capacity is uniquely human.
As upstream education, UBM teaches exactly that ability — to step outside, observe, and reveal the entire behavioral spectrum governing our actions, habits, and skills — then ask how to align it toward our goals and ideals.
One mode is the default, almost always running. The other is an awareness that lets the program program itself — and alter the behavioral home its behaviors live in.
11. “It doesn’t resolve psychology’s deeper theoretical mysteries.”
That’s yet to be determined, actually.
Separating biology from behavior — rather than conflating them — is a step in the right direction. So is the distinction that mind, while uniquely human, has no shared definition, no agreed boundary, and in UBM is not elemental. Which suggests those “deeper mysteries” may be structural. A category error. TBD.
Psychology is bogged down by its own definition: the study of mind and behavior. Mixing the ethereal with the hard and observable is exactly where the fog rolls in. Behavior comes first. UBM steps out of the fog and focuses only on what influences action in the moment and shapes it over time.
Does that crack the deeper mysteries? It may. It may not. Doesn’t matter — it isn’t what UBM was designed to do.
UBM was presented to resolve incoherence and inaccessibility — long held to be two separate crises. UBM demonstrates they are one challenge, and resolves it simply. Elementally.
12. “Behavioral literacy is too complex to teach kids.”
Learning the mechanics of behavior is a lot like learning a new language.
Music is a language. Math is a language. Behavior is a language.
So far, the trend suggests: the younger the student, the faster the assimilation.
Students with fresh eyes tend to grasp it faster. Adults often arrive with decades of assumptions — cups already full.
And the experts?
In a few cases, they’ve struggled with UBM the most.
UBM is upstream education.
It clearly and cleanly identifies the elements — the basic mechanics of behavior — ideally long before anyone ever feels broken.
Not therapy. A simple, clean, clear map.
Maps never guarantee success. But millions use them every day — because they save time, energy, and provide clarity.
The Pattern
Almost every misconception comes from expecting UBM to be something it never claimed to be — a therapy, a predictive model, a specialized branch. The Unified Behavior Model is none of those.
It’s an elemental, unified, goal-directed, and falsifiable MAP of ALL human behavior. It’s an UPSTREAM educational toolkit.
The challenge still stands: find a fifth element. No one has twelve months and counting…
Learn more at unifiedbehaviormodel.com, or read the full Opus 4.8 evaluation.
This post is a companion to the Opus 4.8 adversarial evaluation, where an AI stress-tested UBM for two days and couldn’t break it. Here we take the twelve most common misconceptions and answer each one, plainly.